
“技术故障”背刺巴菲特,金融大模型到底靠不靠谱?
一个“技术问题”,导致巴菲特的伯克希尔-哈撒韦公司股价暴跌近100%。
想必很多小伙伴已经感受过了这则铺天盖地的消息,所带来的亿点点震撼。
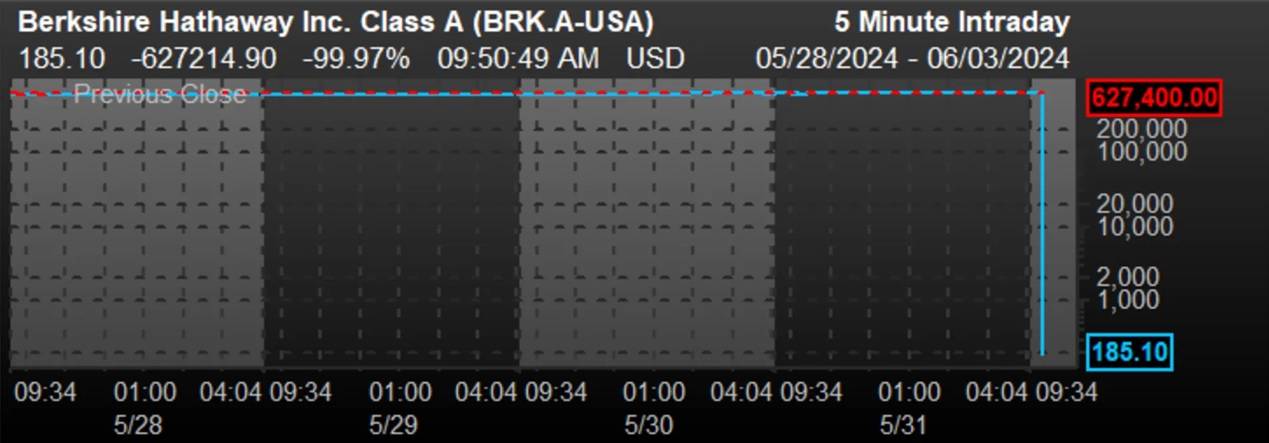
而根据事后的消息来看,这个大故障是纽交所的合并报价系统(CTA)在更新软件时出现了问题。
许多专家都对此做了分析,有人认为是CTA软件在进行版本更新时出现了数据一致性问题;也有人提出最大的问题应该是出现在了数据库。
但总而言之,这并非是纽交所今年来第一次出现的故障,而是众多里的一个:
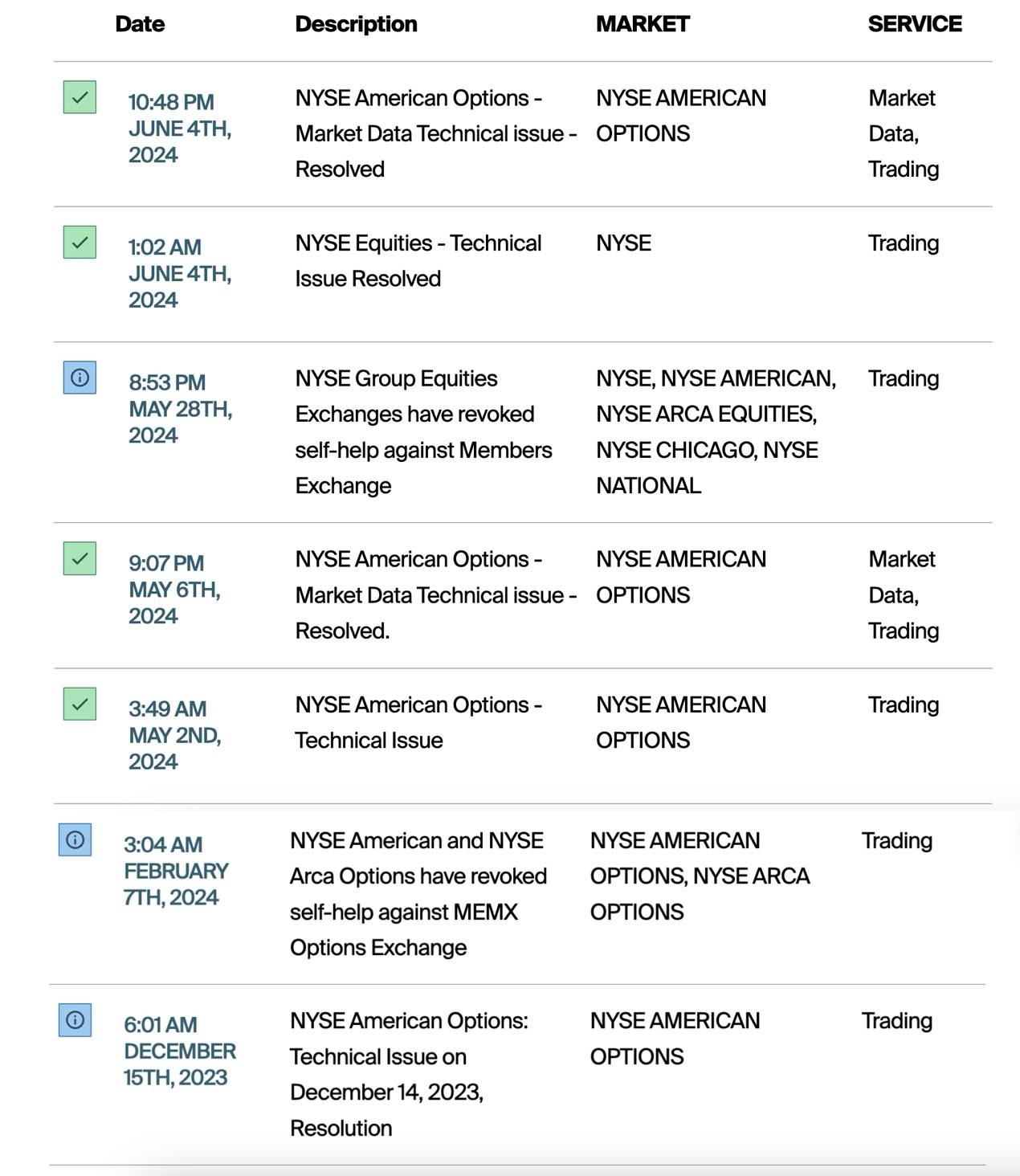
甚至某开源数据库联合创始人Jason直言不讳地表示:
>纽交所在CTA软件上相关的IT水平还不及中国的大型金融机构和互联网公司,在中国已经很少会发生这种低级错误了。
即便如此,这也不禁令人产生更大的顾虑和担忧——
传统软件问题尚能引发如此大的问题,那么站在大模型时代当下,AI+金融,是否又能做到准确可信?
正所谓实践是检验真理唯一标准,要回答的这个问题,我们不妨了解一下已经在金融领域“上岗”了的AI大模型。
大模型上岗金融,都在做什么?
诚然AI大模型的发展已然呈现势不可挡的趋势,但在金融领域真正应用的时候,依旧存在一些显著的困难和挑战。
例如数据隐私和安全方面,金融数据往往高度敏感,涉及个人和企业的财务信息,确保数据隐私和安全是首要挑战之一。
并且这些数据具有多源和异构的特点,需要进行有效的整合和处理,才能确保它们的准确性和完整性。
再如模型本身,大模型往往被视为“黑箱”,因为其内部决策过程难以解释;在金融领域,尤其是涉及风险管理和监管合规时,可解释性和决策透明性是非常重要的。
还有在实时性和资源消耗方面,金融市场瞬息万变,需要实时数据处理和决策支持,大模型的推理涉及到大量的矩阵乘法计算,对硬件的矩阵乘法计算能力提出较高要求,计算复杂性可能导致响应时间延迟,不利于实时应用。
加之大模型训练和推理过程需要大量的计算资源和能量消耗,这对企业的成本和环保要求提出了挑战。
而成立于1998年的老牌金融科技公司金证,面对上述固有的重重困难,却有着自己的一套解法。

在金证看来,大模型的优势在于文本及非结构化数据处理能力、人机交互能力、生成能力和逻辑推理能力较强。
而相比小模型而言,大模型也存在明显的劣势,例如大模型“幻觉”问题(即大模型答非所问),大模型的部署算力要求高造成算力资源浪费,部署成本高等问题。
因此,金证的解法就是——通过组合式AI,即大模型+小模型+工具,以此来支撑各个业务场景AI需求。
大模型方面,包含金证去年年底推出的K-GPT以及业内众多顶流的大模型,在特定的金融任务中发挥大模型的特长。
小模型则是指诸如OCR、NLP、人脸识别、文字识别、财务分析等传统模型,可以细分任务做到快准狠地处理。
至于工具,则是指地图、天气、CRM、邮件、OA等。
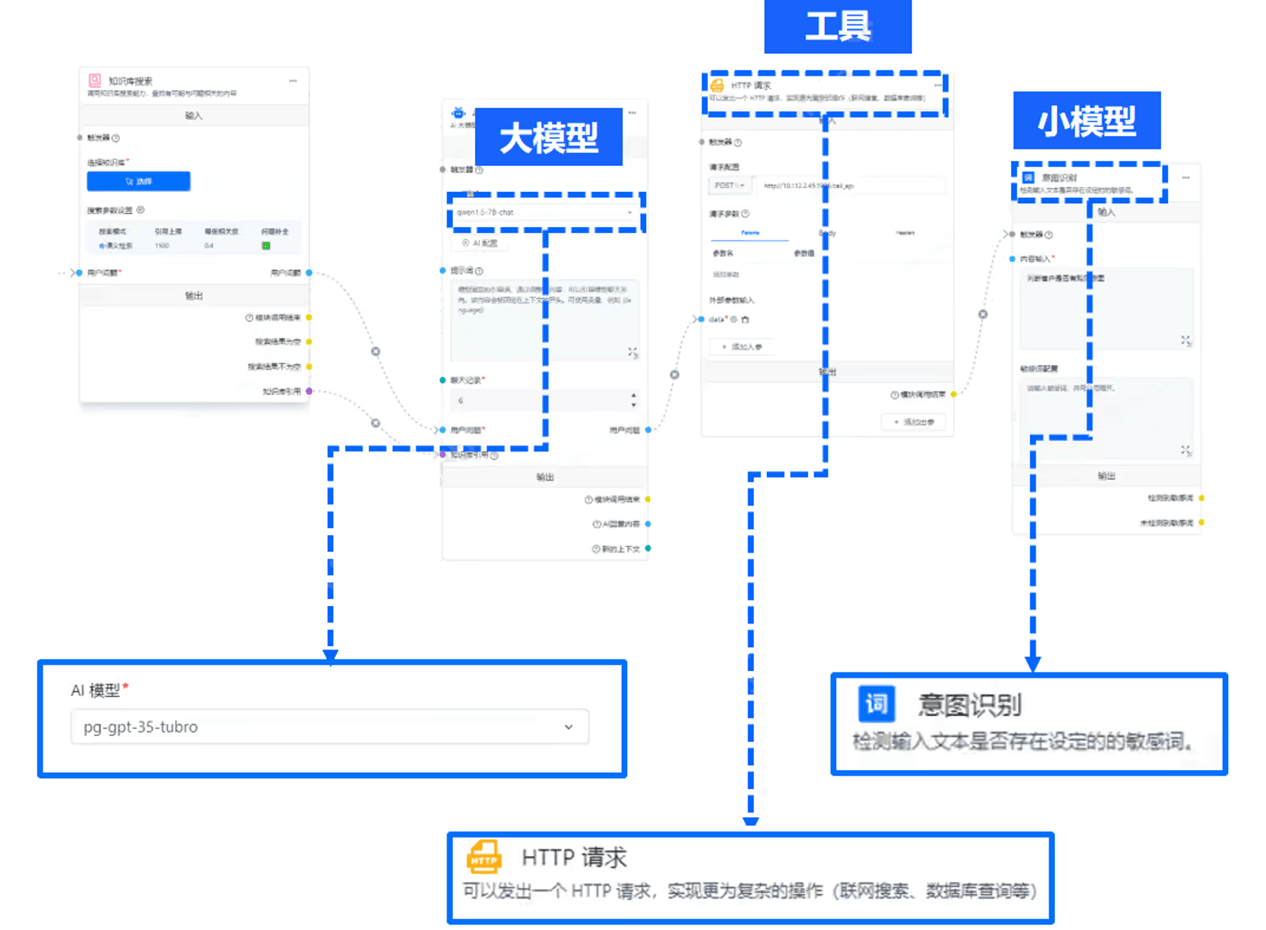
一言蔽之,在某个金融领域任务中,这种模式可以让大模型、小模型和工具做到“专业的人干专业事”,尤其能极大地提高效率。
值得一提的是,相比于通用大模型,金证的K-GPT在数据查询的准确性方面表现更佳,能够更好地理解金融术语,提供专业且数据扎实的回复。

据了解,K-GPT 还支持查看引用的知识源,并具备与实时数据和模块化集成的能力,可以调取实时数据和组件。
依托庞大的金融知识库,K-GPT专为金融场景服务,其核心优势在于对金融的深入理解、数据准确、可验证性以及支持调用Agent功能。
从效果上不难看出,金证已然让大模型在金融领域中合格地上岗,那么针对成本和资源上的痛点,金证又是如何解决的呢?
背后是高带宽内存(HBM)的至强处理器在发力
金证K-GPT方案中,还有一点比较特别:与英特尔合作,采用了基于CPU的大模型推理方案。
据了解,他们主要是看中的是英特尔® 至强® CPU Max 系列处理器。
这是英特尔唯一一款基于x86架构并采用高带宽内存(HBM)的CPU系列,采用了片上HBM设计,内存带宽高达4TB/s。和传统DDR5内存相比,HBM具有更多的访存通道和更长的读取位宽,理论带宽可达DDR5的4倍之多。
要知道,大模型推理涉及大量的权重数据读取,对硬件平台的内存访问带宽提出了很高的要求。
至强® CPU Max具有64GB HBM,每个内核可以分摊到超过1GB的内存,对于包括大模型推理任务在内的绝大多数计算任务,HBM都可以容纳全部的权重数据。

内存带宽还不是金证选择这款CPU的全部理由。
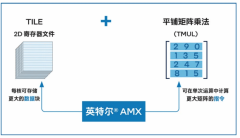
英特尔® 至强® CPU Max系列还内置了英特尔® 高级矩阵扩展 (英特尔®️ AMX)引擎,大幅提升了大规模矩阵乘法运算性能。
金证K-GPT基于Transformer架构,其核心特点包括多头注意力机制和前馈神经网络层,这其中都包含大量矩阵运算,而英特尔® AMX通过1024位TMUL指令和8个独立的矩阵计算单元,可以每时钟周期执行8次独立的矩阵乘累加操作,为这些运算提供强大的加速能力。
如此一来,大模型推理的效果如何呢?
在只用单颗 CPU 的情况下,推理130亿参数大模型,首个词元生成时间就能压到1秒左右,模型推理TPS超过10 tokens/s,用户提问后约2秒内就能得到响应。
别忘了遇到负载高峰等情况,还可以同时启用2颗CPU,性能还能提升将近一倍,可以说足以满足金融场景的大部分应用需求了。

除了硬件层面的突破,英特尔还提供了经过优化的软件工具来挖掘硬件潜力。
比如广泛使用的OpenVINO™ 工具套件,就被用来专门调优加速模型的Embedding处理进行。
金融场景涉及大量专业文档的输入任务,Emedding正是把文本从离散变量转变为连续向量的过程,好让AI能够理解。
经过OpenVINO™ 工具套件优化后,K-GPT大模型的批量Embedding性能提升到3倍之多。
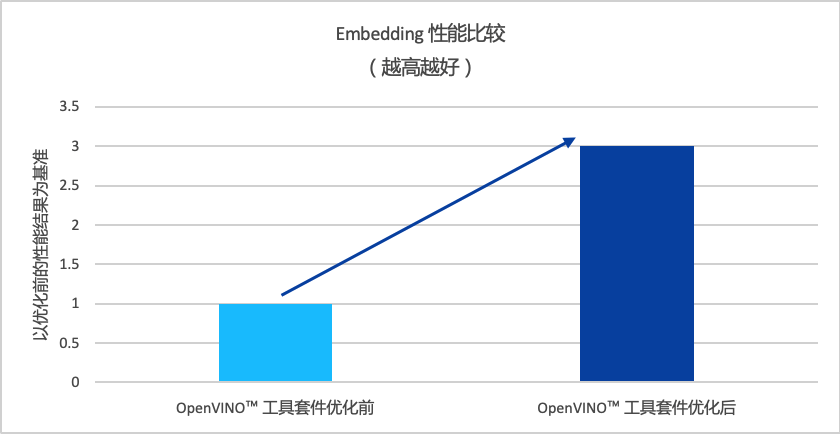
图注:OpenVINO™ 工具套件优化前后 Embedding 性能比较
再比如金证与K-GPT配合使用的开源向量数据库Faiss,英特尔也提供了优化版本,以提升在至强® CPU Max上的模型推理性能。
在大规模向量相似性检索任务中,经英特尔优化过的版本性能可提升至4倍左右。
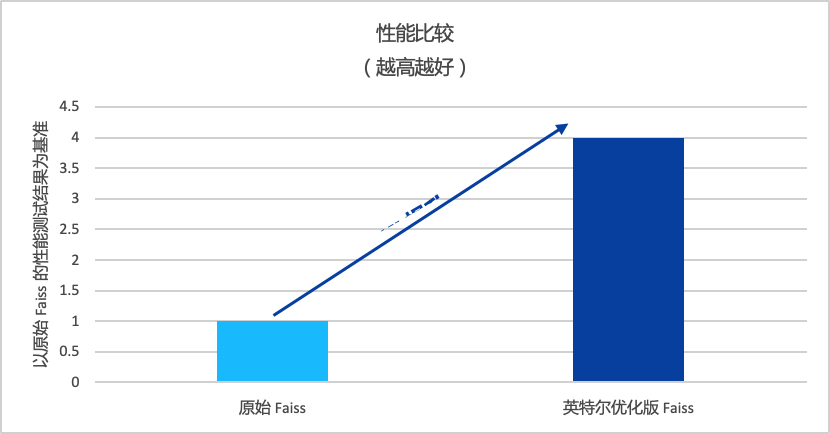
图注:英特尔优化版 Faiss 与原始 Faiss 性能对比(越高越好)
除了性能方面之外,金证选择英特尔® 至强® CPU Max系列作为算力底座还带来其他方面的优势:
首先是灵活性。由于与主流的 x86 架构完全兼容,金证可以继续使用原有的机器,灵活搭配适合自身业务的配置。而且 CPU 能同时应对推理和通用计算,可根据负载情况随时调配资源。
第二是总拥有成本 (TCO)。从长远来看,CPU路线能以更低的部署和维护开销,实现与专用加速器相媲美的性能。这对于需要控制预算的金融机构来说至关重要。
综合看下来,英特尔® 至强® CPU Max系列处理器在硬件能力、软件优化、生态适配、总拥有成本优势等方面都与金融场景非常契合,不失为业界大模型落地的一种新思路。
如何评价?
随着数字化转型的不断深入,大模型为金融行业带来的机遇与挑战并存。
越来越多的金融机构开始探索如何将 AIGC 技术与实际业务相结合,在提质增效的同时控制成本。但总的来说,大模型在金融行业的应用仍处于初步探索阶段。
金证携手英特尔打造的这套大模型推理方案,可谓是应用层、模型层、算力层的深度融合,为业界树立了标杆。
不久前举办的金证科技节,就吸引了众多金融机构前来"取经"。
作为连接金融与科技的重要平台,金证科技节吸引了众多来自银行、证券、保险等领域的金融行业玩家参与,共同探讨 AI 技术在金融领域的应用前景与优质实践。
可以预见,在英特尔的算力加持下,金证将在大模型技术上不断突破,助力更多金融机构实现数字化转型,为用户带来更智能、高效的服务体验。


芯片头条

三星获得高达64亿美元的芯片法案资金,以扩大德克萨斯州的半导体业务
2024-04-16
漂亮手机来了,华为P系列改名Pura
2024-04-16
全球加速碳化硅产能扩充
2024-03-20
ASML推出全新Hyper-NA EUV技术,预计2030年问世引领半导体新篇章
2024-02-28
麒麟9000S供应问题即将解决!华为手机24年冲击1亿部!
2024-01-08








